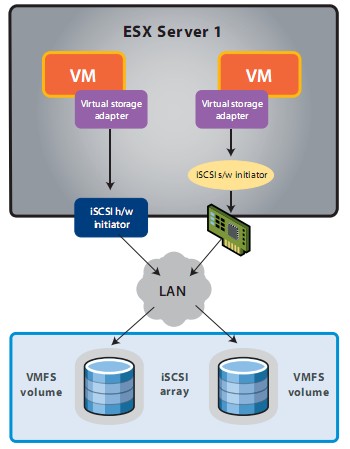
VMware HA permite que multiples hosts ESXi puedan ser configurados como un cluster para proveer de alta disponibilidad y una rapida recuperacion ante fallos, para todas las máquinas virtuales en dichos hosts.
HA protege la disponibiliad de las siguientes formas:
- Protege contra fallas de servidores, reiniciando las máquinas virtuales en otros hosts dentro del cluster.
- Protege contra fallas de aplicaciones monitoreando continuamente una máquina virtual, y reseteandola en caso de detectar una falla.
VMware HA cuenta con las siguientes caracteristicas que lo diferencian de otras soluciones de Clustering tradicionales:
- No se necesita instalar ningún software especial dentro de la aplicación o máquina virtual. Toda la carga de trabajo es protegida por HA, y después que esta es configurada, no se requiere de otras acciones para proteger a las nuevas máquinas virtuales que se vayan agregando en el tiempo. Estas ultimas serán protegidas automáticamente.
- Es posible combinar vSphere HA con DRS (Distributed Resource Scheduler) para proteger contra fallas, y para proveer de balanceo de carga entre todos los hosts dentro de un cluster.
- Reducción de costo en hardware y configuración. Una MV puede ser movida entre los hosts, por lo que se evita la necesidad de duplicar la configuración en multiples máquinas como en otras soluciones de clustering. Solo se requiere contar con suficientes recursos para soportar la caida de 1 o más hosts, dependiendo del nivel de protección que se quiera tener.
Como funciona VMware HA?
HA provee de alta disponibilidad a las MV formando clusters donde residen los hosts y dichas MV. Los hosts en un cluster son monitoreados, y ante la falla de un host, las MV que residen en dicho host son reiniciadas en otros hosts que se encuentren disponibles en el cluster.
En versiones anteriores a vSphere 5, en un cluster HA existian los hosts primarios y secundarios, donde los 5 primeros hosts unidos a un cluster HA, funcionaban como primarios, y el resto como secundarios.
En vSphere 5, cuando se crea un cluster HA, uno de los hosts es designado como "
Master host" o host maestro, para comunicarse con vCenter Server y monitorear el estado de los otros hosts y sus MV. Este host maestro debe ser capaz de detectar y tratar apropiadamente con los diferentes tipos de fallas que pueden afectar a un host. Se debe distinguir, por ejemplo, entre un host con fallas, de uno que ha llegado a estar aislado en la red.
Hosts maestros y esclavos
Cuando un host es unido a un cluster HA, un agente es instalado y configurado en el host, para comunicarse con otros agentes en el cluster. Cada host en un cluster funciona como maestro o esclavo.
Cuando se habilita HA en un cluster, todos los hosts
ACTIVOS participan en una elección para elegir al host maestro del cluster. El host que tenga el mayor numero de datastores montados tiene una ventaja en la elección. Solo existe
1 host maestro por cluster, si este falla, es apagado, o es removido del cluster, se realiza una nueva elección. Estas son las responsabilidades de un host maestro:
- Monitorear el estado de los hosts esclavos. Si uno de estos falla o se encuentra aislado, el host maestro identifica que VM necesitan ser reiniciadas.
- Monitorear el estado de todas las MV protegidas. Si una MV falla, el host maestro se asegura que ésta sea reiniciada. Además, usando un motor de ubicación, el host maestro tambien determina donde se debiera realizar el reinicio.
- Gestiona la lista de hosts y MV protegidas del cluster.
- Actua como interfaz de administración con vCenter Server, y reporta el estado de salud del clister.
Los hosts esclavos contribuyen al cluster ejecutando las MV, monitoreando su estado de ejecución, y reportando las actualizaciones de estado al host maestro. Un host maestro, obviamente, tambien puede hospedar y monitorear MV.
Otra de las funciones realizadas por un host maestro, es la protección de MVs. Cuando se protege una MV, HA garantiza que intentará volver a encenderla despues de una falla (failover). Las MV protegidas son aquellas en estado activo, no considerandose las MV apagadas.
vCenter Server reporta si un host es un host maestro - "
Running (Master)" - o esclavo - "
Connected (Slave)" - usando lo que se conoce como "
vSphere HA host state". Este estado es reportado en el tab "Summary" del host, en el vSphere Client, y en la vista de hosts en un Cluster o Datacenter.
Tipos de falla de Host y su Detección.
Como ya mencionamos, el host maestro en un cluster HA es responsable de detectar la falla en un host esclavo, y dependiendo del tipo de falla detectada, las MV en dicho host podrian ser reiniciadas en otro host. Existen 3 tipo de fallas que pueden ser detectadas:
- Un host deja de funcionar, por ejemplo, por falla de hardware.
- Un host queda aislado en la red.
- Un host pierde conectividad con el host maestro.
El monitoreo del estado de los hosts se realiza a traves del intercambio de heartbeats en la red, cada segundo.
Cuando el host maestro deja de recibir estos heartbeats desde los hosts esclavos, se chequea el estado de conexión del host antes de declararlo como fallido. Este chequeo incluye determinar si el host esclavo está intercambiando heartbeats con uno de los datastores, lo cual veremos en más detalle a continuación. También se comprueba si el host responde a las pruebas de Ping enviadas a su IP de administración.
Si ninguna de estas pruebas es exitosa, el host finalmente es considerado como fallido. En este caso las MV de dicho host son
reiniciadas en otros hosts del mismo cluster.
En cambio, si el host esclavo sigue intercambiando heartbeats con un datastore, el host maestro asume que es un problema de
División de Red o
Aislamiento de red, y continua monitoreando el host y sus MV.
Un aislamiento de red de un host ocurre cuando un host se encuentra aún en funcionamiento, pero no existe comunicacion con los agentes HA a través de la red de administración. En estos casos, el host intenta llegar a traves del comando ping a la dirección de aislamiento del cluster. Si esto ultimo también falla, el host se declara a si mismo como aislado en la red. En este caso, el host maestro monitorea las MV que están en ejecución en el host aislado, y actuará según los parametros configurados en el cluster HA, pudiendo, por ejemplo, reiniciar las MV en otro host, o permitiendo que las MV sigan en ejecución en el host aislado, mientras se soluciona el problema.
División de Red
Cuando ocurre algun fallo en la red de administración en un cluster HA, un conjunto de hosts de dicho cluster podria no ser capaz de comunicarse con los otros hosts a traves de dicha red. Esto puede provocar multiples divisiones en un cluster.
Un cluster dividido provoca degradacion en la protección de las MV, y en las funcionalidades de gestion del cluster:
- Protección de MV: vCenter permite que las MV sean encendidas, pero es protegida solo si esta corriendo en la misma división en la que se encuentra el host maestro que es reponsable de protegerla.
- Gestión del Cluster: En una división, vCenter Server se puede comunicar con solo algunos de los hosts del cluster, y se puede conectar solo a un host maestro. Cambios en la configuración que afecta a HA podrian no tomar efecto hasta solucionar la división, ya que una división podria tener una configuración más nueva que otra.
Nota: Cuando ocurre una división en un cluster HA, solo se pueden agregar host a la división con la que vCenter Server se puede comunicar.
Datastore Heartbeating
Cuando el host maestro en un cluster HA no se puede comunicar con un host esclavo sobre la red de administración, el host maestro utiliza el
Datastore Heartbeating para determinar si el host esclavo a fallado, se encuentra en una división de red, o está aislado en la red. Si el host esclavo ha dejado de realizar el Datastore Heartbeating, es considerado como host fallido y sus MV son reiniciadas en otros hosts del cluster.
vCenter Server selecciona un conjunto preferido de datastores para realizar el heartbeating. La seleccion esta pensada para maximizar el numero de hosts que tienen acceso al datastore, y minimizar la posibilidad de que los datastores se encuentren en el mismo Storage o servidor NFS. Esta selección puede ser modificada manualmente, en los parametros de configuración del cluster. Para todos los efectos, solo se pueden utilizar datastores montados en al menos dos de los hosts disponibles.
Adicionalmente, se puede utilizar el atributo
das.heartbeatdsperhost, para cambiar el numero de datastores seleccionados por vCenter en cada host.
Por defecto se selecciona 2, y el valor maximo es 5.
Control de admisión
HA utiliza control de admisión para asegurarse de que existan suficientes recursos disponibles en el cluster para proveer de alta disponibilidad y asegurarse de que las reservaciones de recursos de las MV sean respetadas.
Existen tres tipos de control de admisión:
- A nivel de Host: Se asegura de que un host tenga suficientes recursos para satisfacer las reservaciones de todas las MV que corran en el.
- A nivel de Resource Pool:Se asegura de que un RP tenga suficientes recursos para satisfacer las reservaciones, shares, y limites de todas las MV en el.
- A nivel de Cluster HA: Se asegura de que se reserven suficientes recursos en un cluster para la recuperación de MV ante la falla de un host.
El control de admision impone restricciones en el uso de recursos y cualquier accion que pudiera violar dichas restricciones, no está permitida, como por ejemplo:
- Encender una MV
- Migrar una MV otro host, cluster o Resource Pool.
- Aumentar la reservacion de memoria o CPU de una MV.
De estos tres tipos de control de admision, solo es posible deshabilitar el control de admisión en un
cluster HA. No obstante, esto
no es considerado una buena practica, ya que no permite asegurar que las MV sean reiniciadas despues de una falla.
En algunos casos, puede ser necesario deshabilitar el control de admision en forma temporal, por ejemplo, durante el mantenimiento de uno o más hosts en un cluster. En estos casos, se recomienda volver a habilitarlo a la brevedad posible.
Politicas de control de admision
El control de admisión en un cluster HA puede ser configurado con una de las 3 politicas de admisión disponibles:
- Tolerar fallas de host en un cluster: permite configurar HA para tolerar un numero especifico de fallas de hosts. Con esta politica de control de admisión, HA se asegura que un numero especifico de hosts puedan fallar, y aun queden suficientes recursos disponibles en el cluster para hospedar a todas las MV de dichos hosts.
En esta politica, HA realiza el control de admisión calculando el Slot Size, lo cual hemos explicado anteriormente.
- Porcentaje de recursos reservados en el cluster: Permite configurar HA para controlar la admisión reservando un porcentaje especifico de los recursos de CPU y Memoria para la recuperación ante la falla de uno o más hosts.
Esta politica utiliza las reservaciones de las MV para aplicar el control de admisión. Si una MV no tiene reservas, se aplican los valores por defecto de 0MB de RAM y 256Mhz de CPU.
- Especificar hosts para failover: Permite configurar HA para designar hosts especificos como hosts para failover. Con esta politica, cuando un host falla, HA intenta reiniciar sus MVs en uno de los hosts especificados para el failover. Si esto no es posible, por la falla de uno de estos hosts designados, o por falta de recursos suficientes, HA intenta reiniciar las MVs en otros hosts en el cluster.
Para asegurar de que exista capacidad suficiente en un host de failover, se evita que una MV sea encendida, o migrada con vMotion a dicho host. Estos hosts además no son utilizados por DRS para el balanceo de carga.
Elegir una politica de control de admision.
Se debiera elegir una politica de control de admisión para HA, basado en las necesidades de disponibilidad, y en las caracteristicas del cluster. Se deben considerar una serie de factores:
- Evitar la fragmentación de recursos, lo cual ocurre cuando hay suficientes recursos en un cluster para las operaciones de failover, no obstante, estos recursos están repartidos en multiples hosts, y por lo tanto no son utilizables porque una MV puede correr sobre solo un host ESXi a la vez. Las politicas "Tolerar fallas de host en un cluster", y "Especificar hosts para failover", se evita esta situacion.
- Flexibilidad en la reservación de los recursos para Failover. Cada politica difiere en la granularidad del control que ellas dan cuando reservan recursos del cluster para failover.
- Heterogeneidad del Cluster. Un cluster puede ser heterogeneo en terminos de la reservación de recursos de MV, y la capacidad total de recursos en los hosts. En un cluster heterogeneo, la politica "Tolerancia a fallas de hosts" es muy conservadora ya que solo considera las reservaciones de la MV más grande cuando se define el Slot Size, y asume la falla del host más grande cuando se calcula la capacidad de failover actual. Las otras dos politicas no son afectadas por la heterogeneidad del cluster.
Recomendaciones
A continuación una serie de recomendaciones a la hora de planificar/configurar un cluster HA.
- Planificar para la renovación de Hardware. Se debe considerar que a medida que el ambiente virtual se vuelve antiguo, el hardware es renovado y/o se agrega nuevo hardware. Estas renovaciones/adiciones en ocasiones pueden provocar problemas de compatibilidad con vMotion. Se debe planificar y configurar un cluster HA pensando en los futuros cambios de hardware, considerando por ejemplo, el uso de Enhanced VMotion Compatibility (EVC)
- Planificar el numero de hosts suficientes en un cluster. Se deben considerar los recursos para las operaciones de failover de MV en un cluster HA.
- Seleccionar la politica de control de admision correcta, deacuerdo a las necesidades de disponibilidad y a las características del cluster que se ha diseñado.
- Al momento de configurar la política de control de admision, no desperdiciar los recursos disponibles. Considerar que:
- No todas las MV son de misión critica o primera prioridad
- Algunas MV pueden permanecer apagadas por un periodo de tiempo ante la caida de un host
- Algunas políticas de control de admisión reservan uno o más hosts para failover, lo cual puede ser un desperdicio de recursos en un cluster pequeño.
- Priorizar el reinicio de las MV durante un failover en un cluster HA.
- No deshabilitar el Control de Admisión. En ocasiones puede ser necesario deshabilitarlo, por ejemplo durante tareas de mantenimiento de uno o más hosts, no obstante, esto solo debe ser una medida temporal, y el control de admisión debe ser habilitado a la brevedad posible.
- Si se utiliza la politica "Porcentaje de recursos reservados en el cluster", esta debe ser ajustada si el tamaño del cluster cambia, por ejemplo, al agregar hosts adicionales al Cluster.
- Utilizar hosts similares. Si los hosts en un cluster tienen diferentes recursos disponibles, podrian afectar el funcionamiento de la politica "Tolerar fallas de host en un cluster", ya que esta reserva el host con más recursos en el cluster. Esto es necesario para proteger todas las MV, pero puede provocar un desperdicio importante de recursos.
- Utilizar shares cuando sea posible, en lugar de usar reservaciones y limites. El uso desmedido de reservaciones puede afectar el Slot Size utilizado por la politica "Tolerar fallas de host en un cluster".
- Asegurar de que todos los hosts en el cluster tengan acceso a los mismos datastores, y a las mismas redes. Esto asegurará que las MV puedan ser reiniciadas en cualquier host al momento de producirse una caida de un host en un cluster.
Espero les haya sido de utilidad, y pronto más novedades en el Blog de Tecnologias Aplicadas!